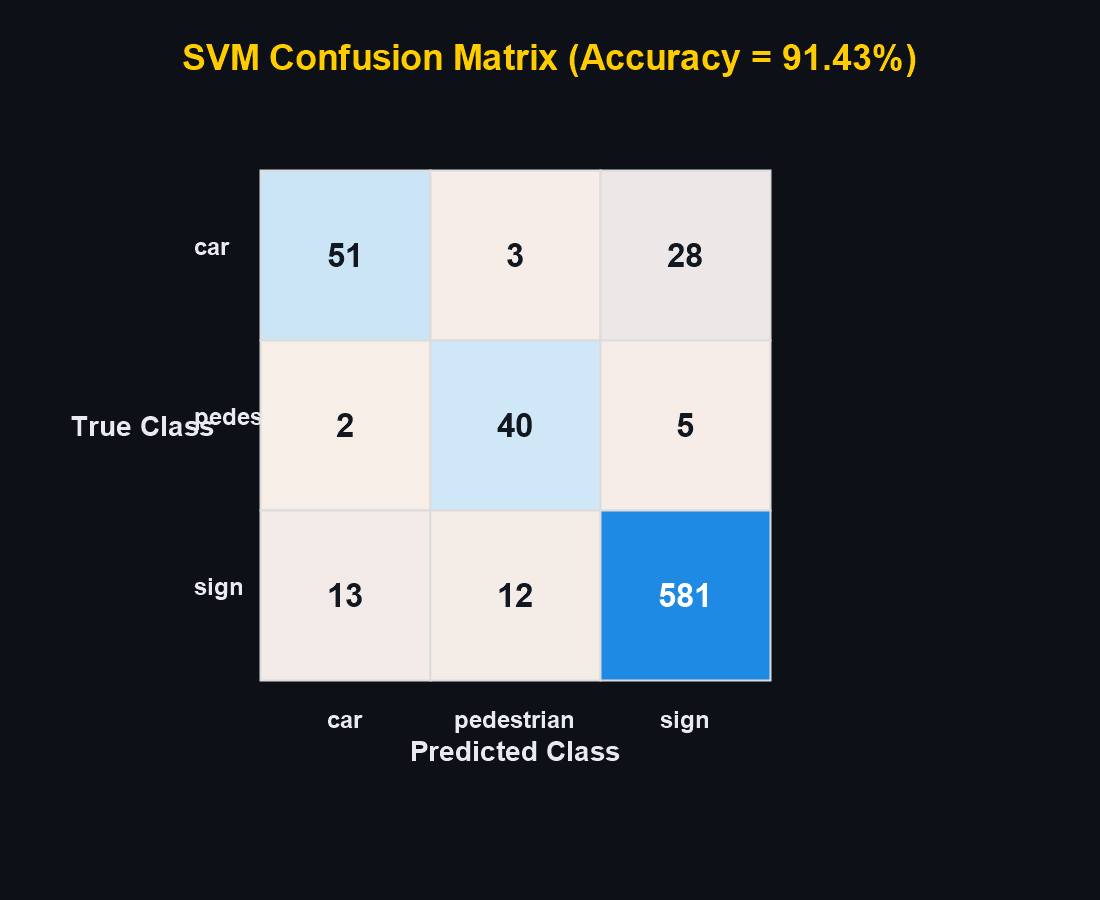
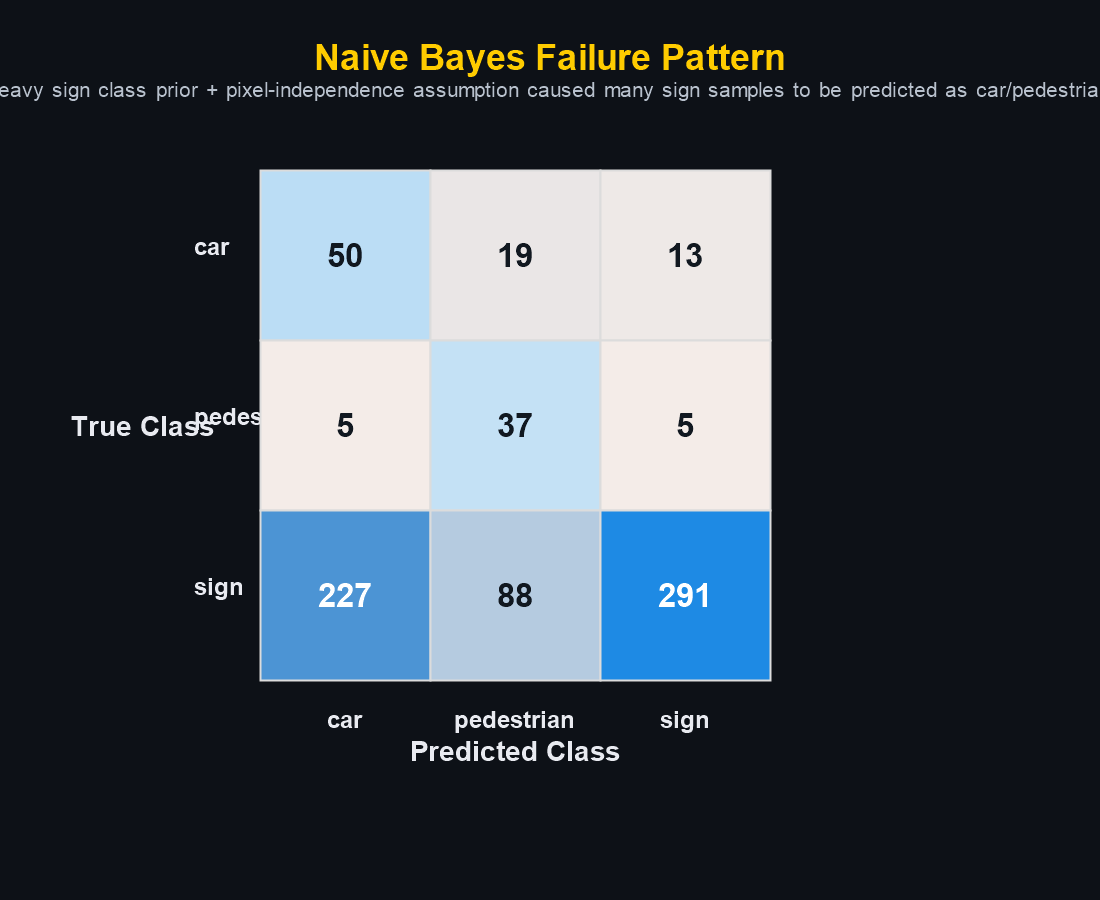
02 — Datasets
What We
Classified
Initially, we struggled finidng good datasets with cropped dash-cam images of the classes we desired.
So we used some suboptimal datasets while we procured and produced our own dataset.
We used labeled datasets from Kaggle and dashcam-related sources.
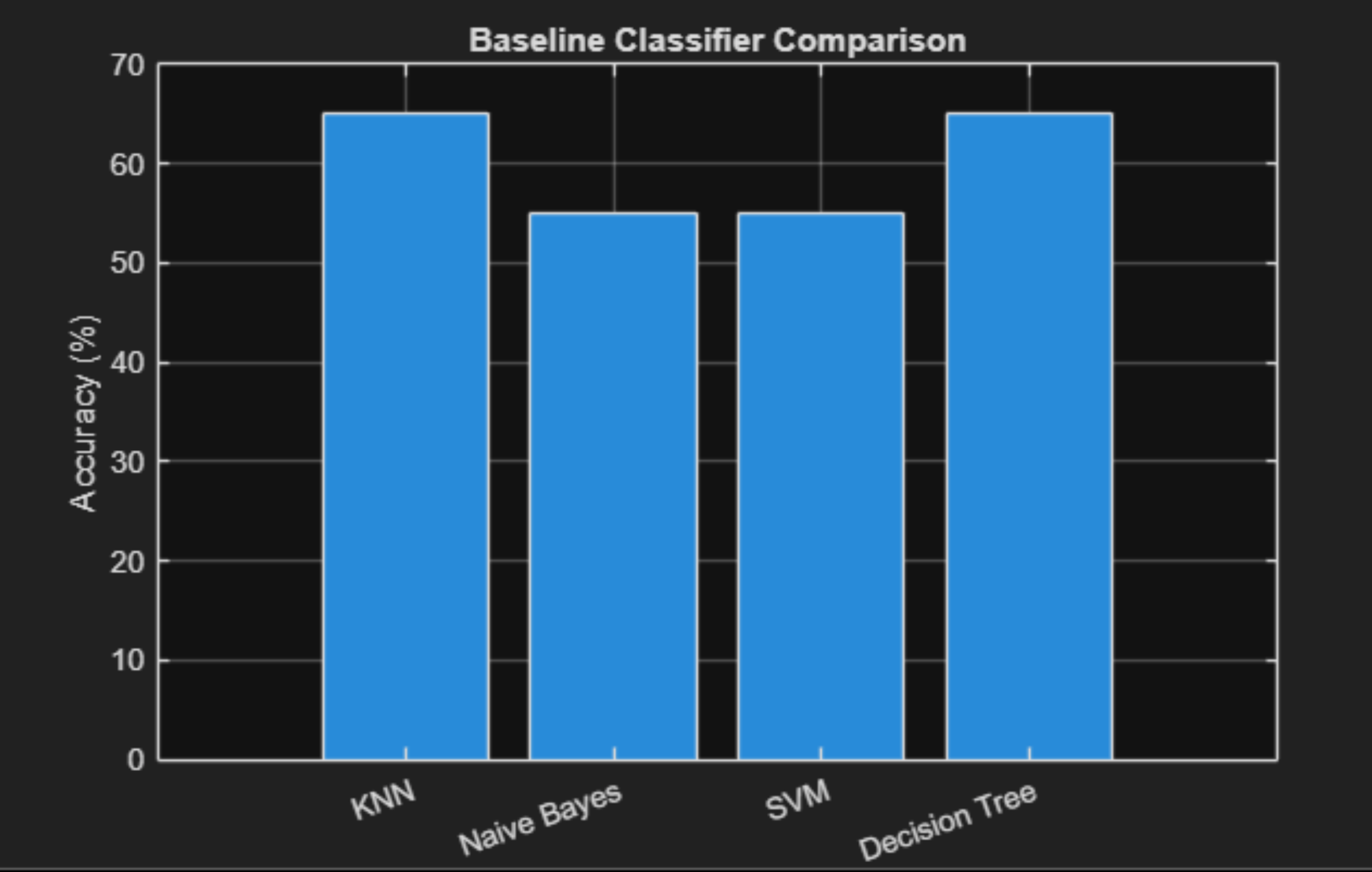
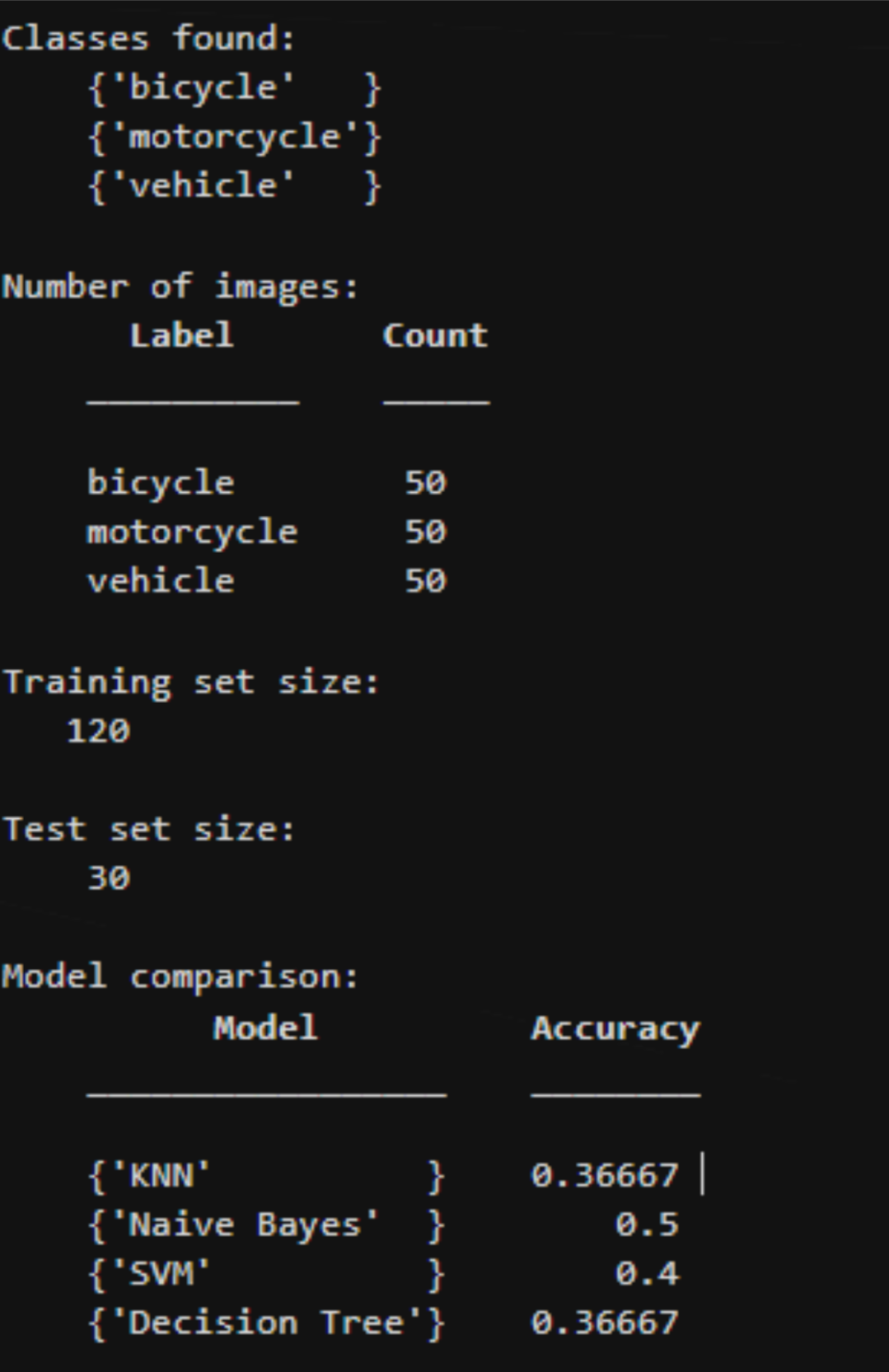
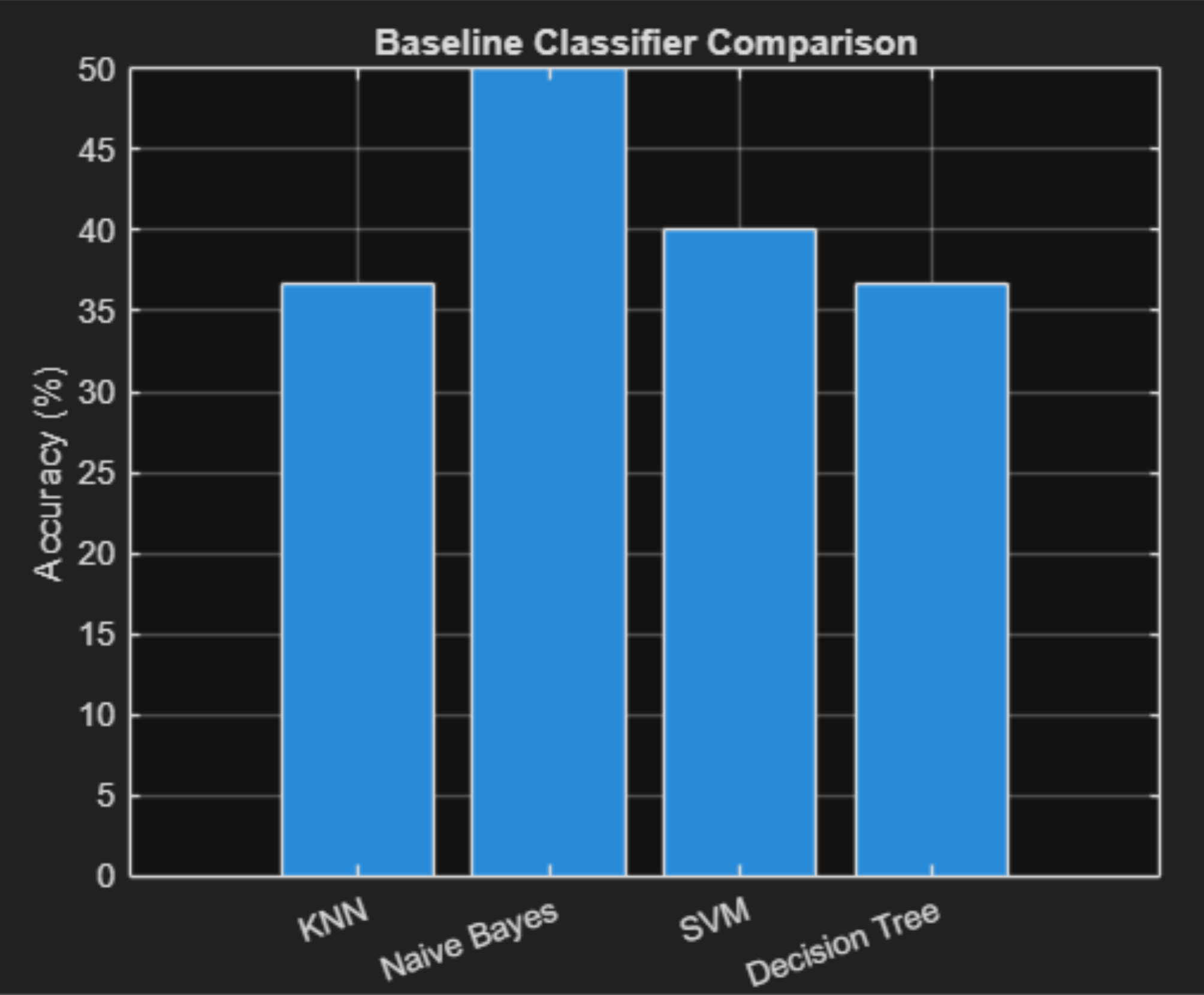
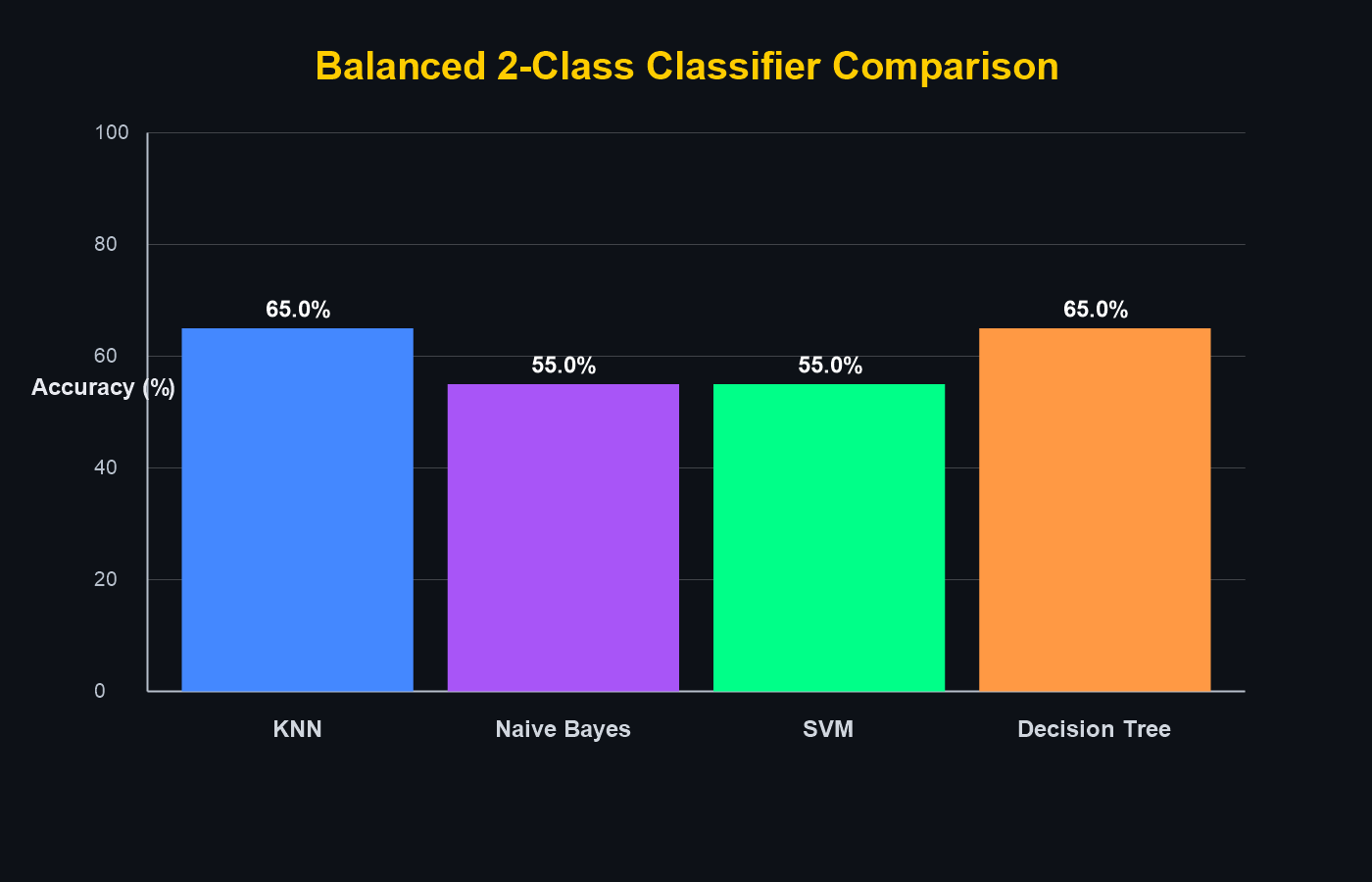
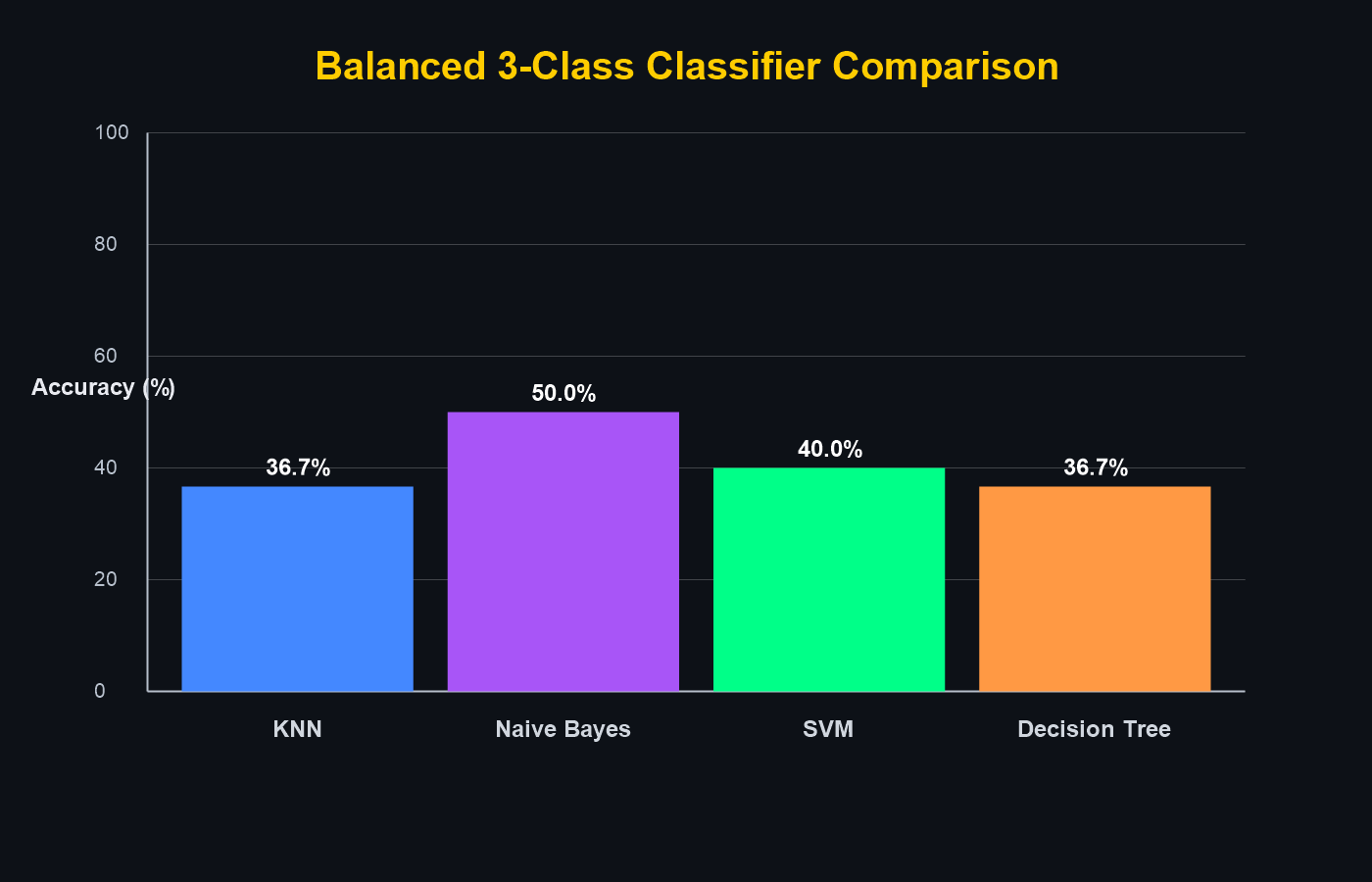
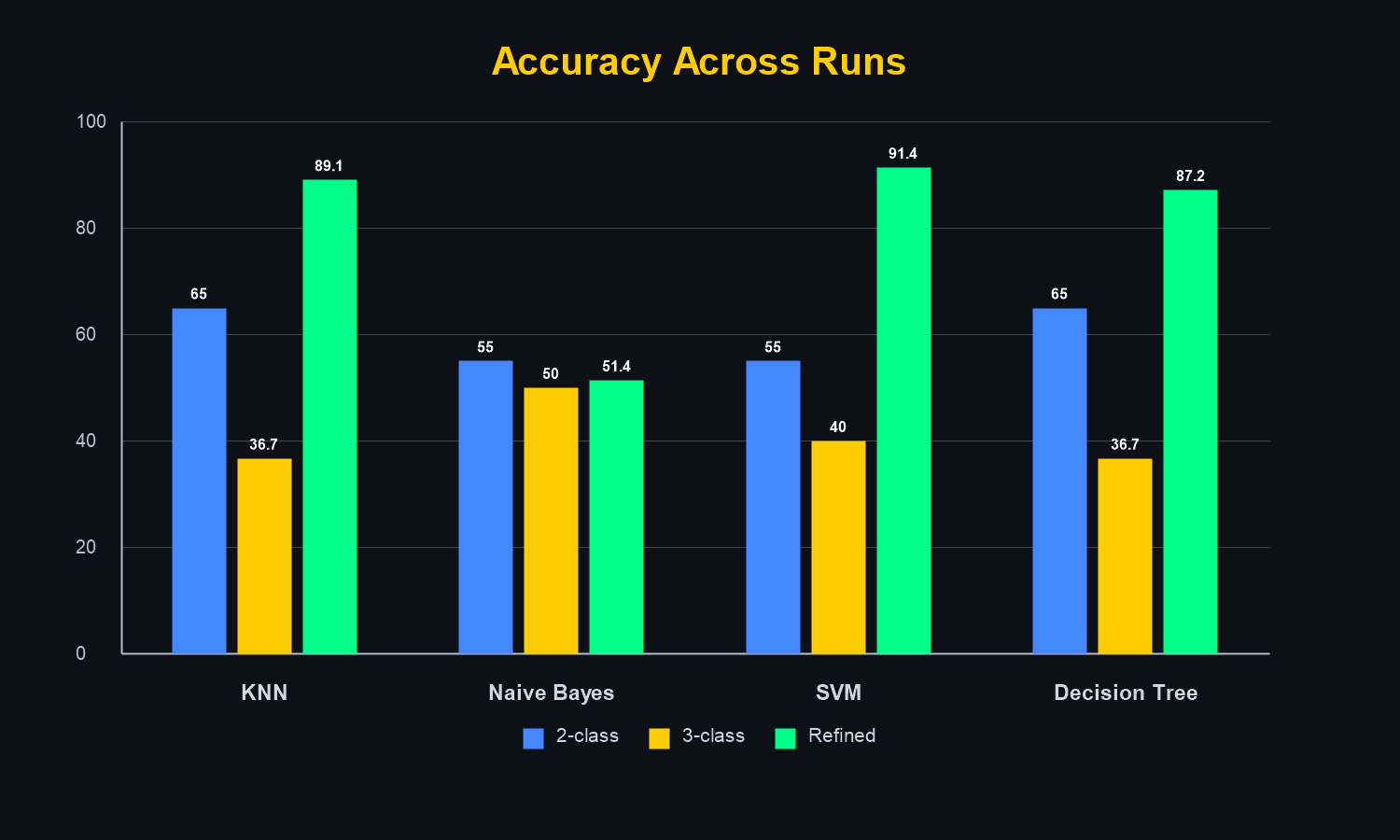
Initial experiments balanced all classes at 50 images each.
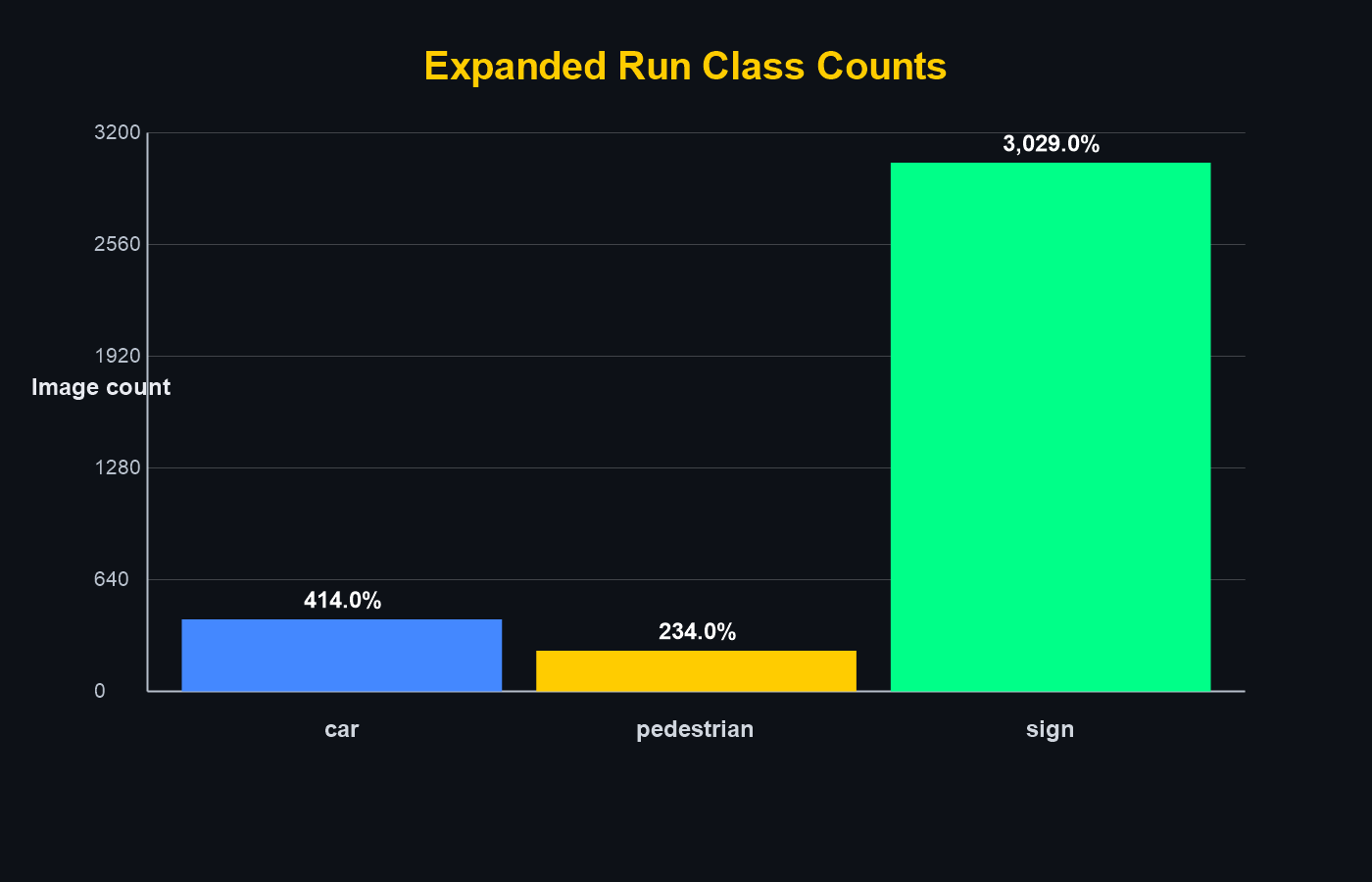
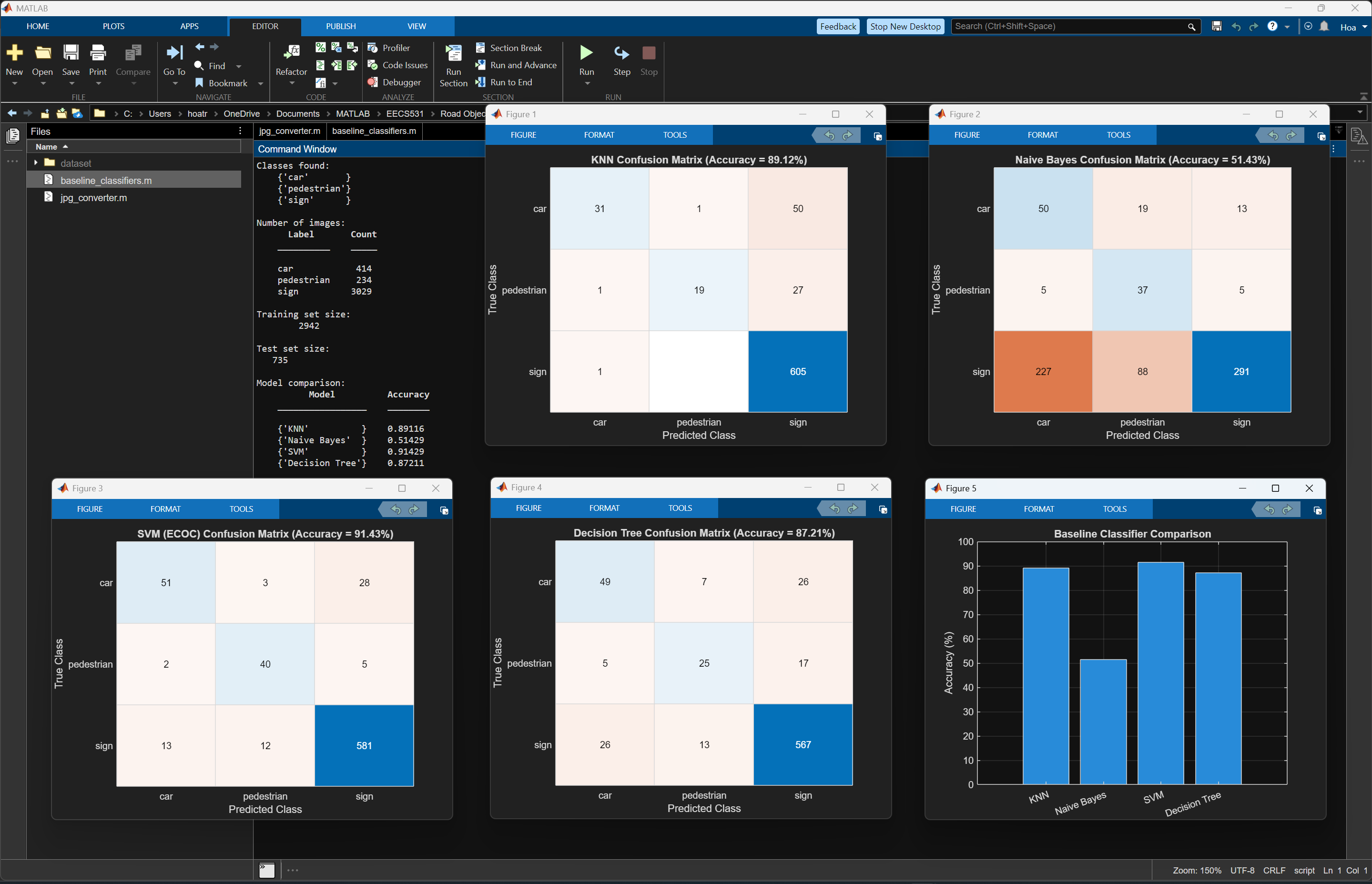
Later runs used unbalanced real-world proportions (e.g. 414 cars, 234 pedestrians, 3029 signs) to better reflect deployment conditions.
To improve realism, we moved away from an older car dataset after finding many images that were not representative of dashcam footage.
It contained luxury vehicles (e.g., Rolls-Royces), heavily edited promotional images, text overlays, and staged settings. Using such images risks teaching the model non-generalizable patterns that would hurt roadside detection in practice.
BadCar(43).jpg is an example of an image that triggered this refinement.
We created part of our own dataset by cropping objects from authentic dashcam footage, improving perspective, lighting, motion blur, and framing consistency.
However, this custom set has limitations: many clips were sourced from Russia and fewer from the United States, Canada, and China.
Pedestrian data may underrepresent demographic, clothing, and environment diversity in North America, which could produce uneven model performance across groups and regions. pedestrian46.jpg exemplifies this limitation.
Expanding to broader demographic and geographic data is an important next step.
All images were in JPG format for their smaller file size and prevalence in real dashcam footage.
- Bicycle — Kaggle balanced subset
- Motorcycle — Kaggle balanced subset
- Vehicle / Car — 414 images (unbalanced run)
- Pedestrian — 234 images (unbalanced run)
- Traffic Sign — 3,029 images (unbalanced run)
- Traffic Light — Kaggle balanced subset
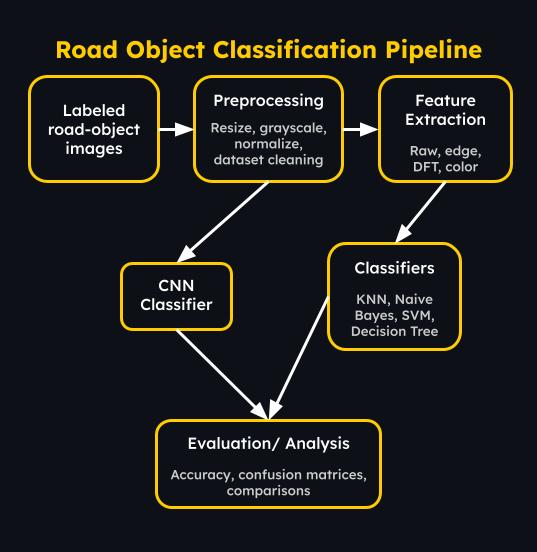
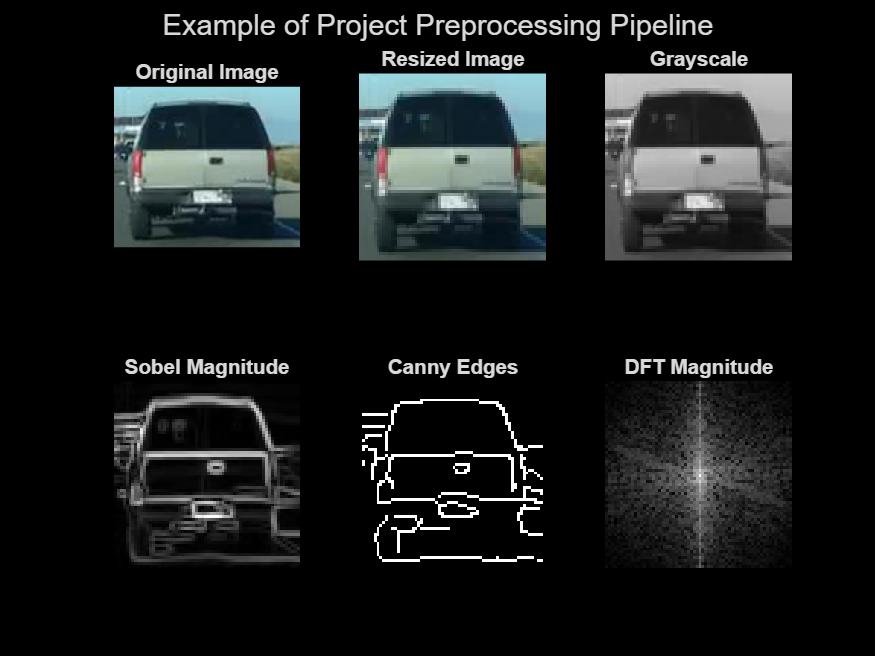


.jpg)